
Understanding OpenAI Completion APIs


Hello everybody,
Many of you may have got chance to try out Open AI APIs, but there are few points which could be overlooked. I will try to shed light on some of those.
Chat completions vs Completions
If you visit the API Reference, there are two completion end points ‘v1/chat/completions’ (Chat completions) and ‘v1/completions‘ (Completions). Which one should you use ?
It is recommended to use the Chat completions end point as only this API serves newer models (Open AI’s most capable model (gpt-4), and the most cost effective model (gpt-3.5-turbo).
More details :

babbage-002 and davinci-002 are GPT base models that can understand and generate natural language or code but are not trained with instruction following.
Let’s dive into understanding the Chat Completions API.
Chat completions API
It is recommended to read API Reference alongside. I will extend this with more clarity on some of the important points.
There are three ways this API can be used :
No Streaming
Generated completion is returned back from the completion APIs as a single response. But, this may take many seconds.
Streaming
To get responses sooner, one can 'stream' the completion as it's being generated. This allows to start printing or processing the beginning of the completion before the full completion is finished.
To enable this, set stream=True
you may have seen this in action while using ChatGPT. Further reading : here
Function calling
Certain OpenAI models (like gpt-3.5-turbo and gpt-4) have been fine-tuned to detect when a function should to be called and respond with the inputs that should be passed to the function.
The following diagram should help to understand how function calling works.
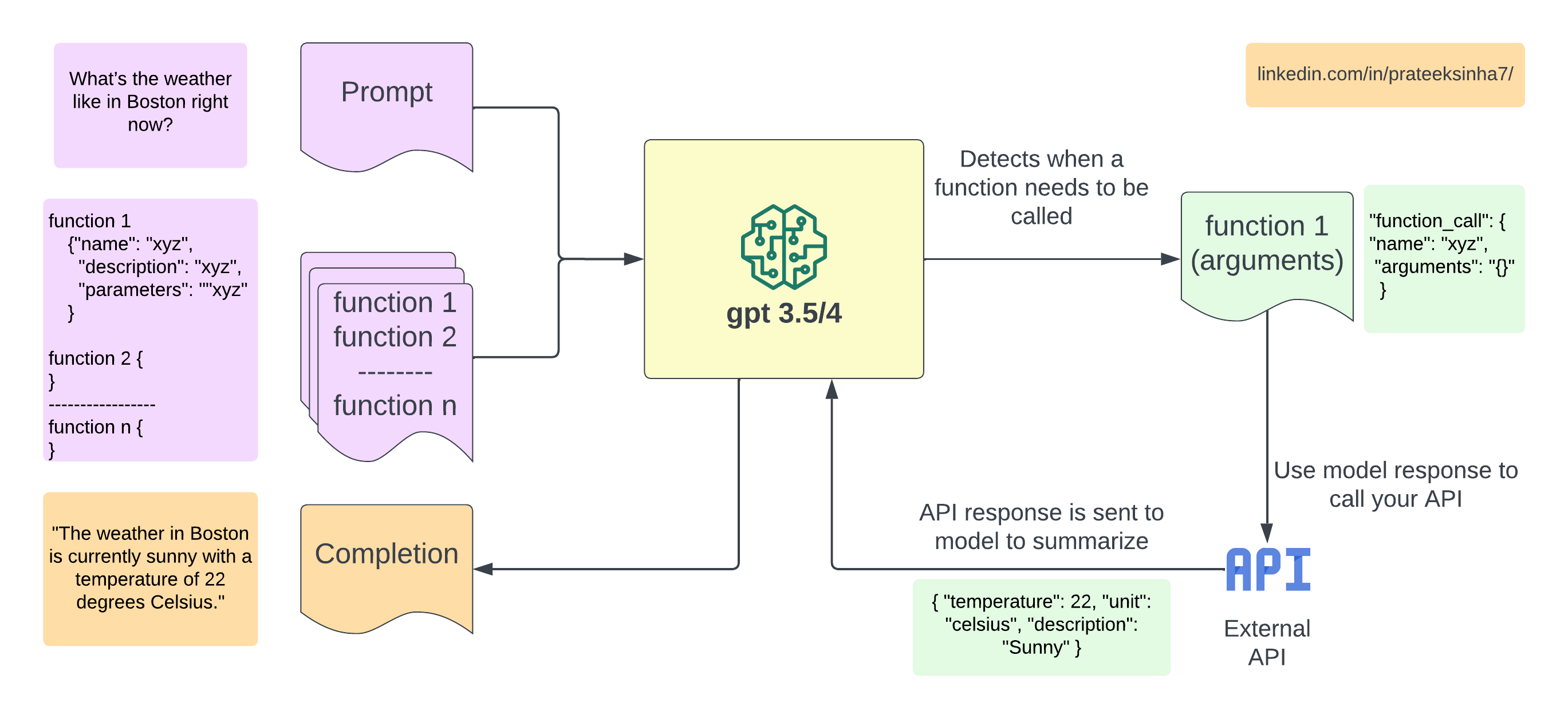
Request Body
The most important inputs in the Request Body are messages, model, temperature/top_p and max_tokens.
Out of these, tunable parameters are messages, temperature/top_p and max_tokens.
messages :
‘messages’ is a list of messages containing conversation. Text of the ‘messages’ is passed with the variable ‘content’ . It is also popularly called prompt. Many times, it is required to engineer/tune prompt to get desired response.
What is ‘role’ in ‘messages’ ?
Each object in messages has a role (either “system”, “user”, or “assistant”).
Typically, a conversation is formatted with a system message first, followed by alternating user and assistant messages.
The system message helps set the behavior of the assistant. For example, we can modify the personality of the assistant or provide specific instructions about how it should behave throughout the conversation. However note that the system message is optional and the model’s behavior without a system message is likely to be similar to using a generic message such as “You are a helpful assistant.”
The main point to note here is that we should send our messages/prompt with role -‘user’
Temperature :
Temperature value ranges from 0 to 1. Lower values for temperature result in more consistent/deterministic outputs, while higher values generate more diverse and creative results.
For Temperature = 0 , if you submit the same prompt multiple times, the model would always return identical or very similar completions.

Generally, temperature = 0 works well for most tasks.
Higher temperature may be useful for tasks where variety or creativity are desired, or we need to generate a few variations for our end users or human experts to choose from.
For example : For a pet name generator, we probably want to be able to generate a lot of name ideas. A moderate temperature of 0.6 should work well.
top_p
This is alternative to temperature.
max_tokens
This is to define the maximum number of tokens to be generated. As you must know already, that tokens are not exactly words, they can be sub-words as well. As a thumb rule, number of words is 75 % of the number of tokens.
Also, the total length of input tokens and generated tokens is limited by the model’s context length.
Hope, I was able to clear the dust over some important points related to understanding the end points provided by OpenAI.